利用队列实现高效率线程池
ruby
接上条,最开始通过轮询空闲线程分配任务实现,结果cpu上下文切换次数每秒一万次左右,实际执行下来效率也很低,直到改用队列:
class Concurrency
SLEEP_DURATION = 0.000001
READY_STATE = 'ready'
PROCESSING_STATE = 'processing'
def initialize(**options)
@max_thread = options[:max] || 22
pool = Rails.configuration.database_configuration[Rails.env]["pool"]
raise PoorDbPool.new("You set max thread #@max_thread, but your database config pool is #{pool}, threads should less than pool") if pool < @max_thread
@sleep_duration = options[:sleep_duration] || SLEEP_DURATION
@threads = []
@queue = Queue.new
while @threads.length < @max_thread
@threads << Thread.new do
thr_start = proc do
loop do
Thread.current[:status] = READY_STATE
exec_content = @queue.pop
Thread.current[:status] = PROCESSING_STATE
exec_content.call
end
end
with_db_query = options[:with_db_query].nil? ? true : options[:with_db_query]
if with_db_query
ActiveRecord::Base.connection_pool.with_connection(&thr_start)
else
thr_start.call
end
end
end
nil
end
def exec(&blk)
raise ArgumentError.new('no block given') unless blk
@queue.push blk
end
# 同步等待所有任务执行完毕
def promise
sleep(@sleep_duration) until @queue.length.zero? && @threads.all?{ |t| t[:status] == READY_STATE }
end
# 同步等待任务执行完毕,立即释放线程以及数据库连接资源
def wait
sleep(@sleep_duration) while @queue.length > 0
while @threads.any?{ |t| t.alive? } do
sleep(@sleep_duration)
@threads.select { |t| t.alive? && t[:status] == READY_STATE }.each(&:kill)
end
end
class PoorDbPool < StandardError; end
end
benchmark:
co = Concurrency.new max: 10, with_db_query: false
Benchmark.bm do |x|
x.report do
10000000.times do |i|
co.exec {i+1}
end
co.wait
end
end
执行结果

查看cpu每秒上下文切换次数$ pidstat -w 1
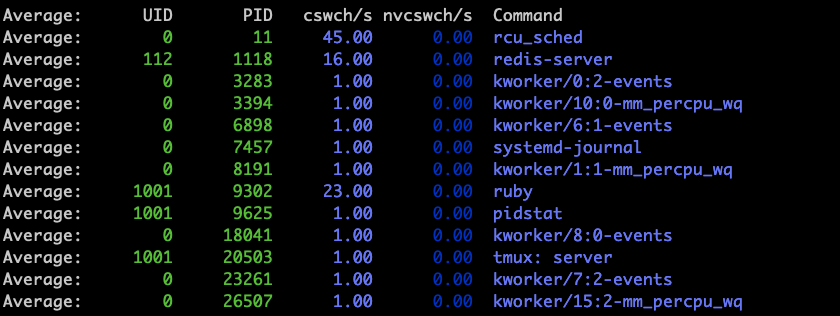
可以看到在非I/O密集条件下,6秒多的时间内,执行了1千万次任务,但是cpu每秒在ruby进程上的上下文切换次数只有10-30。使用队列,在结束上一个任务,可以立马进行下一个任务,很多时候避免了切换线程,大大减少上下文切换的消耗。
cpu切换一次线程,耗时大概是几us,如果每次任务都切换线程,那么光系统切换1千万次线程的成本本身可能就是几十秒,所以对比起来,感觉效率尚可。
大家都知道,在计算密集型条件下,使用多线程,由于上下文切换,效率反而降低,下面对比不使用线程:
Benchmark.bm do |x|
x.report do
10000000.times do |i|
(->{i+1}).call
end
end
end
结果和使用了线程池差不多,时间花销略低一点:

如果不使用 Proc 呢:
Benchmark.bm do |x|
x.report do
10000000.times do |i|
i+1
end
end
end
结果:

可以看出,其实最大花销都在 Proc 上,不知道这里有没有优化的点。
如有不对,或者改进的地方,请指正。
发表于 2020.06.04
© 自由转载 - 非商用 - 非衍生 - 保持署名
PrevNext